Where Does the LLM's Knowledge Come From?
Chapter 5: Where Does the LLM’s Knowledge Come From?
In this chapter we will focus on the origins of LLMs’ (Large Language Models) data and will outline the diverse data sources: from massive web crawls to curated sets of books. You will see how each source contributes unique insights and accuracy and directly impacts the reliability of AI-generated content.
Understanding the LLM’s training data is key to understanding its capabilities and biases. Let’s look at the foundational training data for OpenAI’s GPT-3, a model that marked a significant leap in LLM capabilities:
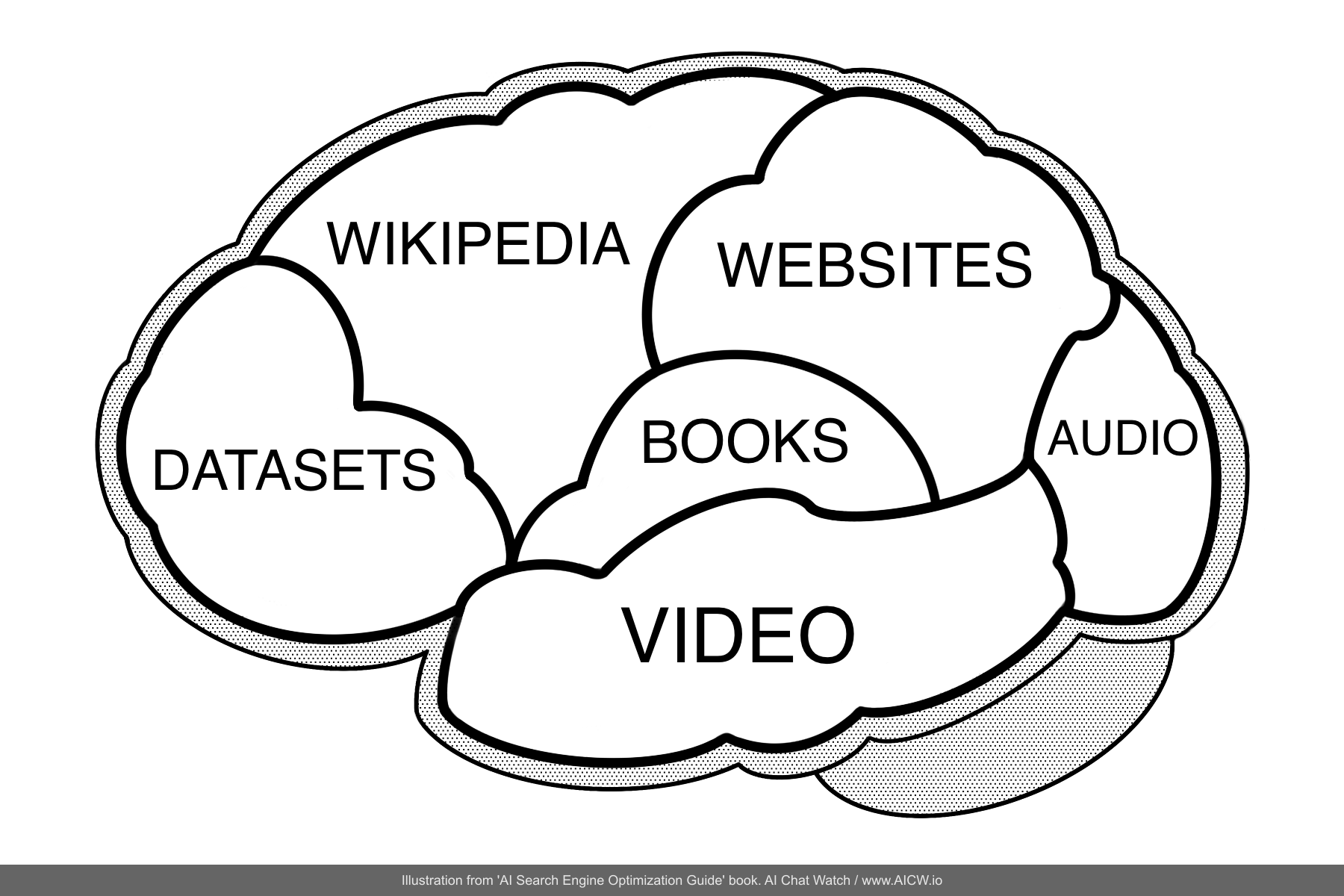
Figure 5.1. Foundational training dataset composition for OpenAI’s GPT-3 model.
(Source: Data adapted from OpenAI research paper - Arxiv:2005.14165[^22], accessed Dec 2024)
Common Crawl
This dataset is the largest component of the training data! Think of it as a monthly snapshot of the whole public Internet. It is petabytes in size (one petabyte is 1000 terabytes) and provides a monthly copy of over 2 billion html pages. It is maintained by a non-profit organization called Common Crawl located in California.
Website owners can actually explore this dataset to see what parts of their site are included in this dataset at index.commoncrawl.org. You can search your domain, see captured pages, download data segments, and even check the robots.txt file Common Crawl saw during its crawl.
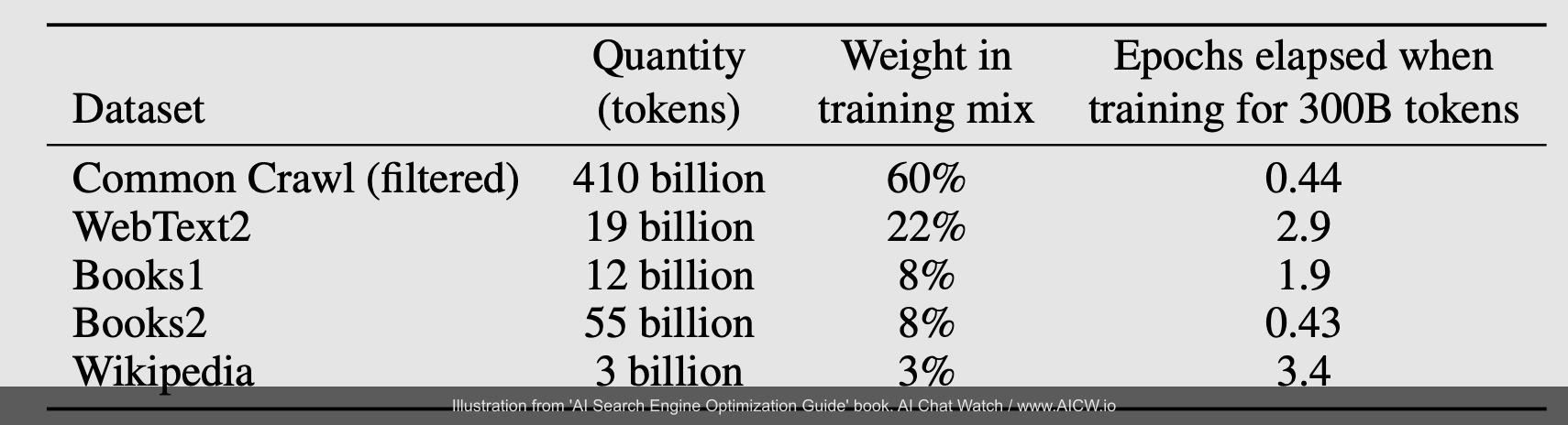
Figure 5.2. The Common Crawl Index Server interface, allowing users to search the index by domain pattern.
(Source: index.commoncrawl.org, accessed Dec 2024)
For example, this search for *.aisearchwatch.com found an compressed zip file with all website pages captured into the dataset for AISearchWatch.com:
Figure 5.3. Example view of data structure within a Common Crawl WARC file, showing captured URL metadata. (Source: index.commoncrawl.org, data view from specific WARC file, accessed Dec 2024)
WebText2 (curated by Reddit)
This dataset contains dozens of gigabytes of content grabbed from links shared and upvoted on Reddit over 15 years. Each page required a minimum of three upvotes to be included, so Reddit users effectively served as curators to filter for higher-quality links. Although this approach yields more curated content than a raw Common Crawl, it may also introduce biases toward the Reddit community’s interests, which lean heavily toward entertainment. For instance, r/funny[^23] forum has around 67 million users, while r/science[^24] has about 34 million users[^25].
Books (Books1 & Books2 datasets)
The Books1 dataset was collected from thousands of fiction books by indie authors on the Smashwords[^26] self-publishing platform[^27]. The content of the Books2 dataset was not officially disclosed, but it is believed to contain both public-domain books (published before 1927 and thus no longer under copyright) plus modern copyrighted books. OpenAI later stated that it excluded[^28] the Books1 and Books2 datasets from model versions after GPT-3.
Wikipedia
Wikipedia is a large, high-quality, multilingual dataset that covers nearly all human knowledge. Despite its thorough curation, it may still reflect certain editorial or volunteer-driven biases, similar to those found in the broader Wikipedia community. Like WebText2, it was given a higher weighting than some other datasets during AI training[^29].
As you see, different sources are given different weights (i.e. importance). Some are more reputable, others are less reputable. But it is easy to see that Wikipedia and WebText2 (which used upvotes from Reddit) acted as reputable sources because they are based on human curated content in one way or another. A similar set of datasets will likely be used for new models in addition to other other reputable sources. While GPT-3 heavily used book corpora, OpenAI later stated that books were explicitly excluded from subsequent training rounds, potentially due to copyright concerns. In recent years, AI developers like OpenAI have actively expanded their training sources through strategic partnerships
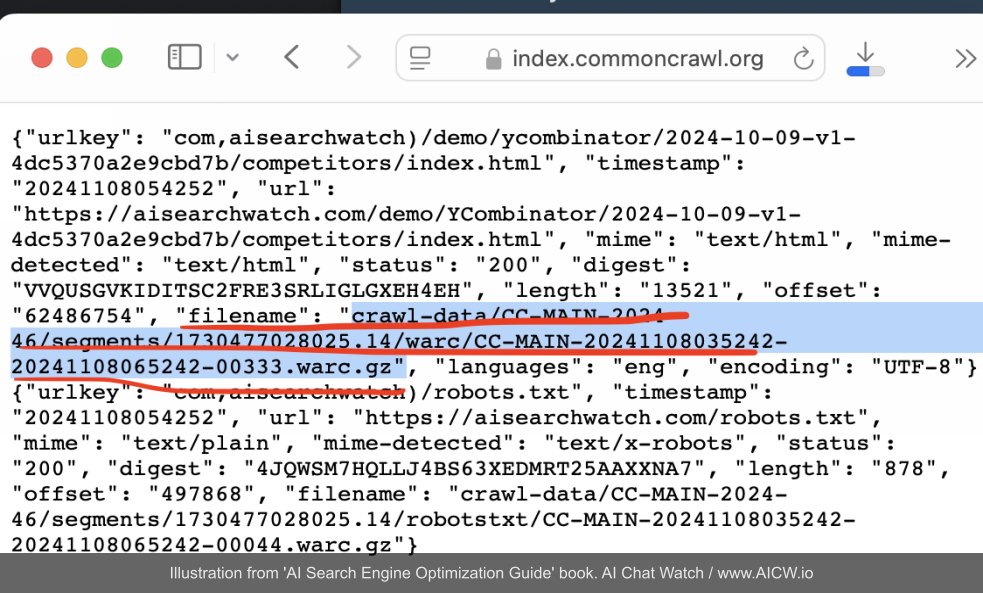
Figure 5.4. Logos representing some of OpenAI’s strategic partners for acquiring training data, including publishers and online platforms. (Source: Logos property of respective companies; compiled by author to illustrate Open AI’s partnerships [^30] [^31] [^32])
-
Major Publishers: deals with News Corp, Axel Springer, TIME, The Atlantic, The Wall Street Journal, Financial Times, and others provide access to high-quality, curated news and editorial content[^33] [^34].
-
Online Platforms: partnerships with Reddit (community discussions), Stack Overflow (technical Q&A, code), and Shutterstock (image descriptions, visual context) add diverse, specialized data.
This hybrid approach for collecting training from both public and closed sources serves two purposes:
- Allows to maintain broad coverage from the public web (through datasets like Common Crawl);
- Strategically incorporates high-quality, verified, and often more current information from trusted partners. This directly impacts the knowledge base AI search engines draw upon.
Understanding sources of AI training data offers important insights into the strengths and limitations of modern LLMs which serve as the “brains” behind AI with and without web search. With this background in mind, we will now discuss how to produce content in a way that AI will best understand and remember.
